
CLRS 한글판을 보면 목차에 푸시-재명명, 재명명후-앞보내기 알고리즘이라고 있다. 뭔가 힙하고 새로워보이는 알고리즘같아 살펴보니 Push-Relabel을 한국어로 번역하다가 나온 이름이었다. (...) 그런 의미에서 이번 포스트에서는 Push-Relabel에 대해 알아본다. Push-Relabel도 1984년에 나온 비교적 최신 논문에 들어있다. SCC로 유명한 Tarjan이 저자로 있다! 해당 논문에 명시적으로 Push-Relabel이라는 알고리즘 이름은 없지만 전해 내려오면서 지어진 이름인 것 같다.
소개
네트워크에서 전송 가능한 데이터를 계산하는 등 유량을 계산하는 것은 중요하다. Push-Relabel도 이러한 최대 유량을 구하는 알고리즘이며 $O(NM^2)$을 가지는 에드먼드 카프나 $O(N^2M)$을 가지는 디닉보다 성능이 좋고 더 개선할 수 있는 잠재력을 가진 훌륭한 알고리즘이다. 기본 Push-Relabel 알고리즘은 $O(N^3)$의 시간복잡도를 가진다. ($N$은 정점의 개수, $M$은 간선의 개수) 보통 유량을 구하는 그래프가 $M \ge N-1$인 점을 생각하면 우수하고 $M = N^2$인 Dense graph를 생각해도 혁신적인 알고리즘이다. 논문에 다양한 유량 알고리즘이 모여있으니 관심있으면 보도록 하자! (위키에도 있다.)
사전 정의
이 알고리즘은 정점에 높이라는 개념을 도입한다. 폭포가 위에서 아래로 흐르듯 Push-Relabel에서 유량은 높이가 높은 정점에서 낮은 정점으로 흐른다. 정점 $v$의 높이를 $h(v)$로 나타낸다. 유량을 구할 땐 source 정점 $s$ 와 sink 정점 $t$ 가 있고 $h(s) = N, h(t) = 0$이다. 그 외 정점 $v$에서 $h(v) = 0$이다. $s, t$를 제외한 정점들은 높이가 0부터 시작해서 높아질 것이고 $N$보다 커질 수 있다.
Push-Relabel은 다른 유량 알고리즘과 다르게 초과량이라는 개념을 도입한다. 다른 유량 알고리즘은 그 동작 과정에서 어떤 정점으로 들어온 유량의 합과 나가는 유량의 합이 동일함이 유지되며 동작한다. 하지만 Push-Relabel은 다를 수 있으며 들어오는 유량의 합이 나가는 유량의 합보다 클 수도 있다. 어떤 정점 $v$가 가지고 있는 초과량을 $ex(v)$라고 정의하고 초기 상태에서 $ex(s) = \infty$ 나머지 정점들의 $ex(v) = 0$이다.
다른 유량 알고리즘과 마찬가지로 $(u, v) \in E$에서 $f(u, v) = -f(v, u)$이다.
Push 연산
Push 연산은 현재 정점이 가지고 있는 초과량을 인접한 정점들에게 흘려주는 연산이다. 이 때 인접한 정점의 높이는 현재 정점의 높이보다 낮아야 한다. 즉 정점 $u$에서 정점 $v$로 Push 연산을 한다는 것은 다음과 같다.
- $h(u) > h(v)$일 경우에만 동작한다.
- $ex(u) > 0$이면 $flow = \min(ex(u), c(u, v) - f(u,v))$를 정점 $v$에게 흘려준다. 그 후 $ex(v)$에 $flow$만큼 더한다.
- 정점 $v$가 Push 받기 전 초과량이 0이었다면 큐에 추가한다.
$c(u, v)$는 $u$에서 $v$로 갈 수 있는 용량이고 $f(u, v)$는 현재 흐르고 있는 유량이다.
Relabel 연산
Relabel 연산은 현재 정점이 다른 가능한 모든 정점에 Push 연산을 했음에도 초과량이 남아있을 경우 추가적으로 흘려줄 정점을 찾기 위해 또는 역간선에 유량을 흘려주기 위해 수행한다. 현재 정점의 높이를 다른 노드에 Push할 수 있도록 높이를 Relabling하는 작업이다. 정점 $u$에서 Relabel 연산을 한다는 것은 다음과 같다.
- 현재 정점에서 흘려줄 수 있는 유량이 있는 다른 정점들 중 높이가 가장 낮은 정점의 높이 + 1 을 현재 정점의 높이로 지정한다.
Push-Relabel
Push-Relabel 알고리즘은 시작 정점에서부터 시작하여 source와 sink 정점을 제외한 정점들의 초과량이 0이 될 때까지 Push와 Relabel연산을 수행한다. 단, 시작 정점은 초과량이 $\infty$이므로 Push 연산만 수행한다. 최대 유량의 값은 정점 $t$ 초과량이 된다.
예제
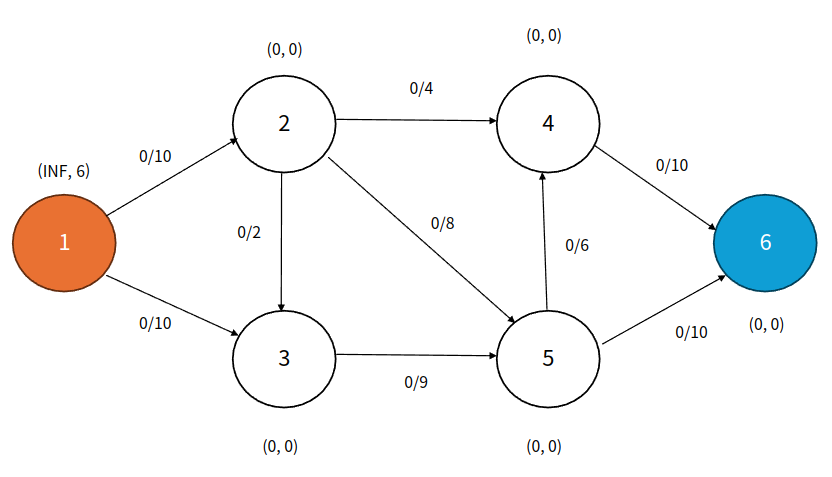
위키에서 유명한 flow 예제이다. 간선에 존재하는 $A / B$에서 $A$는 현재 흐르는 유량의 양이고 $B$는 해당 간선의 용량을 의미한다. 정점에 존재하는 $(A, B)$에서 $A$는 초과량, $B$는 정점의 높이를 의미한다. source 정점은 1번이고 sink 정점은 6번이다. 즉 1번 정점에서 6번 정점으로 흐르는 최대 유량을 구할 것이다.
Step 1

큐: 2, 3
source 정점인 1번에서 인접한 가능한 정점들로 Push 연산을 진행한다. 2번과 3번 정점의 초과량이 증가한 것을 확인할 수 있다. 2번과 3번 정점은 초과량이 0인 상태에서 Push 받았으므로 큐에 추가한다.
Step 2

큐: 3
큐에서 2번 정점을 꺼냈으나 높이때문에 다른 정점으로 Push 할 수 없으므로 Relabel 작업을 수행한다. 1, 3, 4, 5번으로 Push할 수 있으므로 그 중 가장 낮은 높이 + 1인 1로 2번 정점의 높이를 업데이트한다. 여기서 1번에도 Push할 수 있음에 유의하자!
Step 3
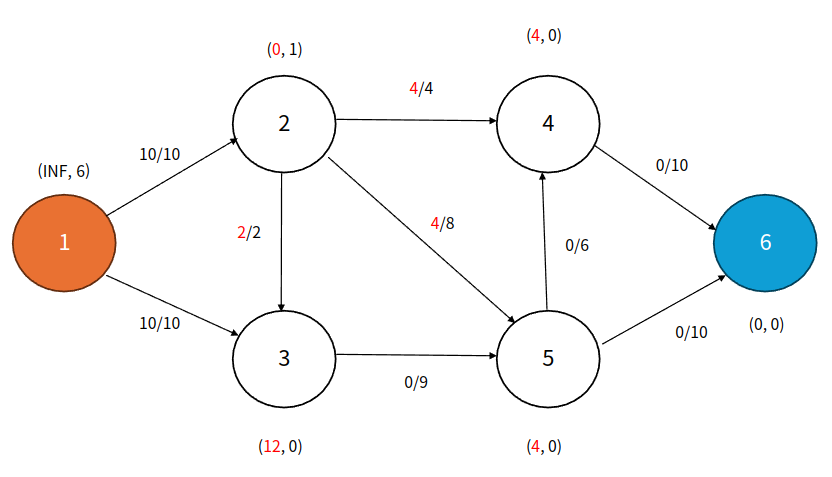
큐: 3, 4, 5
이제 Push할 수 있게 됐다! 남은 초과량을 다른 정점들로 Push한다. 보통 정점 번호가 작은 것 부터 Push한다. 여기서 4, 5번은 초과량이 0이었으므로 큐에 추가한다.
Step 4
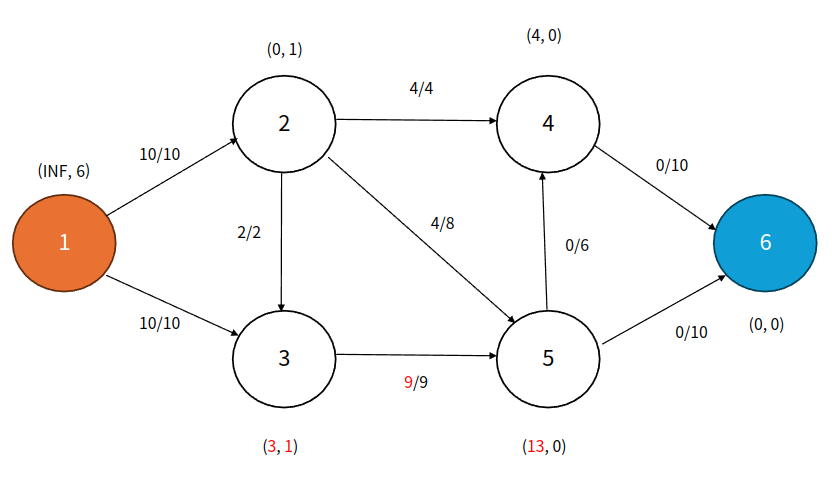
큐: 4, 5
큐에서 3번 정점을 꺼내고 Relabel 한 후에 5번정점으로 Push한다. 5번은 위에서 Push받았으므로 큐에 추가하지 않는다. 하지만 Push했음에도 초과량이 남아있다.
Step 5

큐: 4, 5, 2
1번과 2번 정점으로 Push할 수 있으므로 그 중 낮은 높이 + 1인 2로 Relabel하고 2번으로 유량을 Push한다. 그래도 초과량이 남아있다. 그리고 2는 Push받기 전에 초과량이 0이었으므로 다시 큐에 넣는다.
Step 6

큐: 4, 5, 2
1번 정점으로 Push하기 위해 3번 정점을 Relabel하고 Push한다. 이제 초과량이 0이다.
Step 7

큐: 5, 2
큐에서 4번 정점을 꺼내고 Relabel후 6번 정점으로 Push한다. 4번 정점의 초과량은 0이 된다. 6번 정점은 Push받기 전에 초과량이 0이었으나 sink 정점이므로 큐에 넣을 필요가 없다.
Step 8

큐: 2
큐에서 5번 정점을 꺼내고 Relabel 후 6번 정점으로 Push하고 초과량이 남았으므로 Relabel 후 2번 정점으로 Push한다.
Step 9
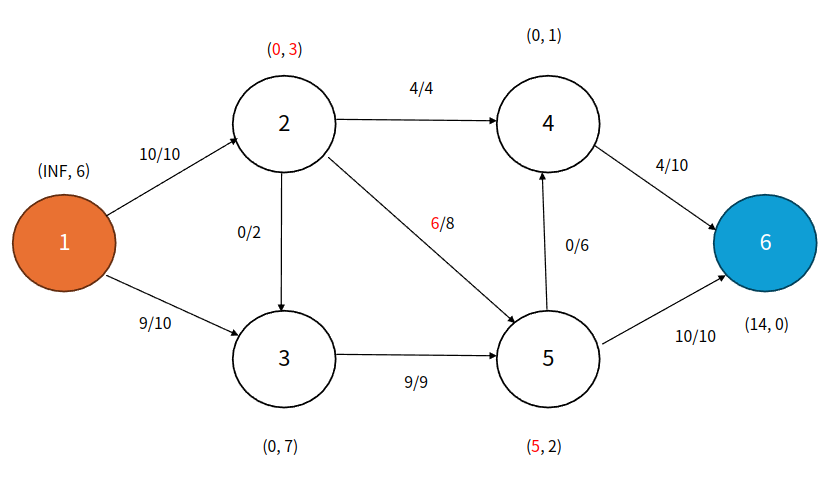
큐: 5
큐에서 2번 정점을 꺼내고 Relabel한 후 5번 정점으로 Push한다. 5번 정점은 Push 전에 초과량이 0이었으므로 큐에 추가한다.
Step 10
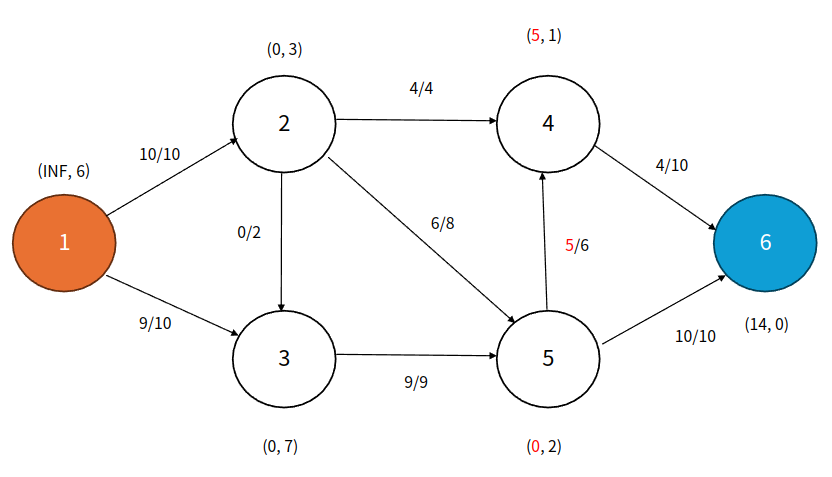
큐: 4
큐에서 5번 정점을 꺼내고 4번 정점으로 Push한다. 이미 높이가 더 높으므로 Relabel할 필요가 없다. 4는 Push 전에 초과량이 0이었으므로 큐에 추가한다.
Step 11

큐에서 4번 정점을 꺼내고 6번 정점으로 Push한다. 이미 높이가 더 높으므로 Relabel할 필요가 없다.
이제 source와 sink를 제외한 모든 정점의 들어오는 flow와 나가는 flow의 값이 같은 상태(초과량이 0)가 되었다. 이 상태에서 sink노드의 초과량인 19가 최대 유량이 된다.
코드
class PushRelabel
{
public:
const int INF = 1LL << 60;
int n;
vector<vector<int>> flow, capacity;
queue<int> q;
vector<int> ex, h;
PushRelabel(int n)
{
this->n = n;
flow.resize(n);
capacity.resize(n);
ex.resize(n);
h.resize(n);
for (int i = 0; i < n; i++)
{
flow[i].resize(n);
capacity[i].resize(n);
}
}
void add(int u, int v, int t)
{
capacity[u][v] = t;
}
void push(int u, int v)
{
if (ex[v] == 0)
q.push(v);
int d = min(ex[u], capacity[u][v] - flow[u][v]);
flow[u][v] += d;
flow[v][u] -= d;
ex[u] -= d;
ex[v] += d;
}
void relabel(int u, int &v)
{
int d = INF;
for (int i = 0; i < n; i++)
if (capacity[u][i] - flow[u][i] > 0)
d = min(d, h[i]);
if (d < INF)
h[u] = d + 1;
v = 0;
}
int max_flow(int s, int t)
{
h[s] = n;
ex[s] = INF;
for (int i = 0; i < n; i++)
if (i != s)
push(s, i);
while (!q.empty())
{
int u = q.front();
q.pop();
if (u == s || u == t)
continue;
int v = 0;
while (ex[u])
{
if (v < n)
{
if (capacity[u][v] - flow[u][v] > 0 && h[u] > h[v])
push(u, v);
v++;
}
else
relabel(u, v);
}
}
return ex[t];
}
};
Push-Relabel의 시간복잡도는 $O(N^3)$이라고 하는데 여기에는 복잡한 분석이 들어가는 것 같다. 그래서 지금은 남기지 않는다.
Push-Relabel은 이 시간복잡도보다 더 개선할 수 있다. 논문의 Chapter 5를 보면 Use of Dynamic Tree라고 해서 링크 컷 트리같은 Dynamic Tree를 사용해서 시간복잡도를 $O(NM \log(\frac{N^2}{M}))$까지 개선했다! $M=N^2$인 Dense한 그래프라면 기존이랑 같겠지만 웬만해서 그런 경우는 잘 없으므로 뛰어난 성능을 보인다. 아직 링크 컷 트리가 뭔지 모르기때문에 이해하진 못했지만 공부해서 어떤 아이디어인지 보고싶다.
'프로그래밍 > 알고리즘' 카테고리의 다른 글
| [알고리즘] Pollard rho 알고리즘 (0) | 2024.09.28 |
|---|---|
| [알고리즘] Suffix Automaton (0) | 2024.09.09 |
| [알고리즘] Berlekamp-Massey 알고리즘 톺아보기 (2) | 2024.07.24 |
| [알고리즘] 현대모비스 알고리즘 경진대회 2024 후기 (2) | 2024.07.07 |
| [알고리즘] 서울대학교 SCSC 프로그래밍 경진대회 후기 (2) | 2024.06.06 |